Michael, from the popular YouTube channel VSauce, recently published a video titled The Zipf Mystery, wherein he talks about several aspects of Zipf's Law:
Zipf's law states that given some corpus of natural language utterances, the frequency of any word is inversely proportional to its rank in the frequency table. Thus the most frequent word will occur approximately twice as often as the second most frequent word, three times as often as the third most frequent word, etc.
It was a pretty interesting video, and I realized I have access to a large repository of words in the form of Xamarin's Developer Portal. So I wondered, will the contents of Xamarin's documentation [1] adhere to Zipf's Law?
As I had recently been learning the R programming language, I figured doing a bit of analysis would be some good practice. To start, I knew that I would need a way to tokenize each piece of content into individual words. The following function simply takes a string, and breaks it into a vector of individual words [2]:
tokenize <- function(str) {
str <- gsub("[^[:alnum:]'’]", " ", tolower(str))
str <- strsplit(str, " ")
}
Next is a function that would tokenize an entire file:
getwords <- function(path) {
lines <- readLines(path)
tokenized <- sapply(lines, tokenize)
unlisted <- unlist(tokenized, recursive=T)
words <- unlisted[unlisted != ""]
return (words)
}
Finally, we just get a list of all markdown files in a given directory, apply the getwords function, and use the table and sort functions to count the number of individual words, and sort them accordingly.
files <- list.files("~/dev/xamarin/documentation", "index.md", recursive=T, full.names=T)
allwords <- unlist(sapply(files, getwords), recursive=T)
t <- table(allwords)
tsorted <- sort(t, decreasing=T)
Lastly, we produce a log plot of the data:
plot(tsorted,log = "xy")
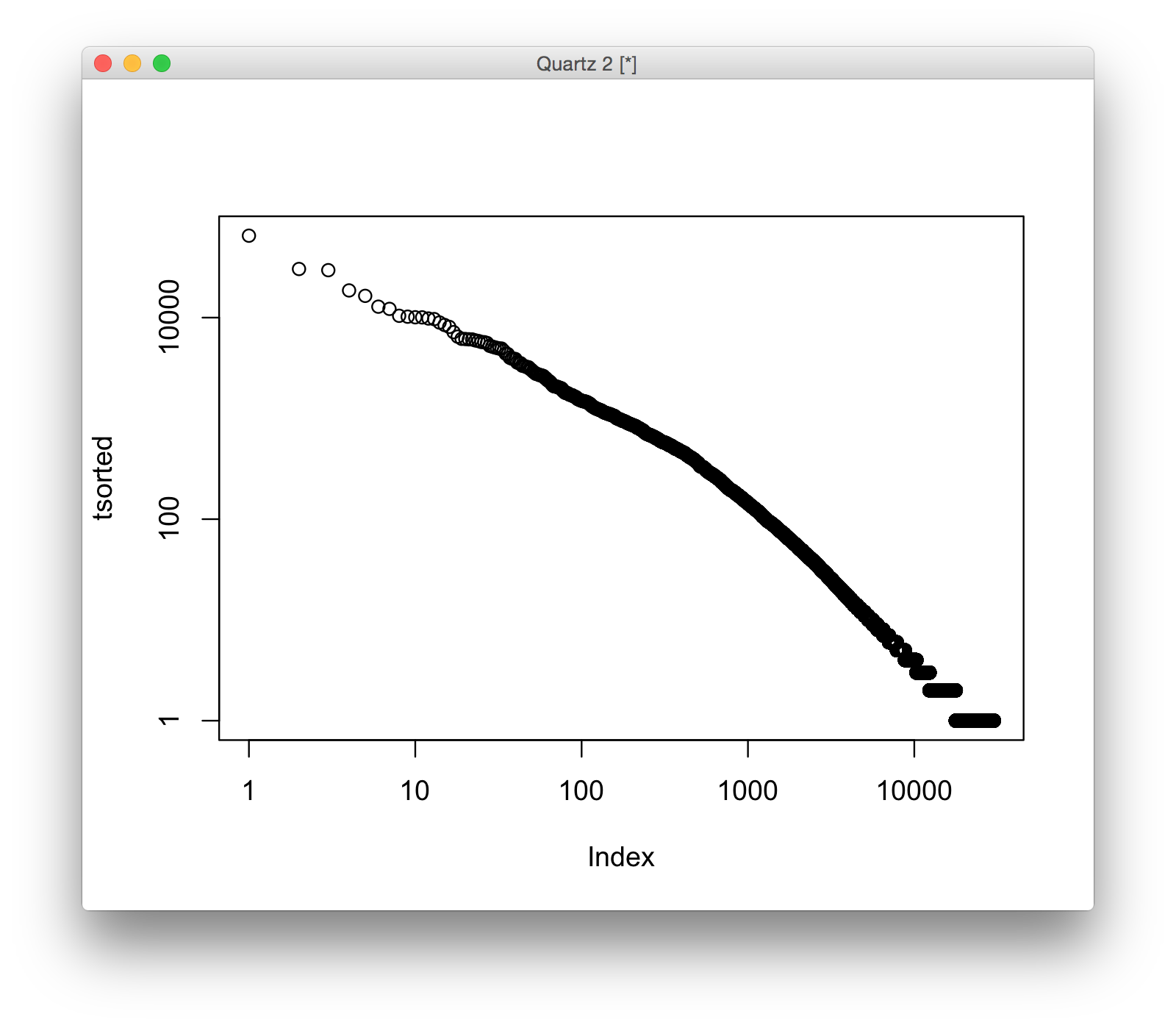
The word usage in our documentation (as of this post) perfectly follows the power-law distribution described in Zipf's Law! Ok, so what else could I pull from this data ... well, according to VSauce, the top 5 most commonly used english words are: "the," "of," "and," "to," "a,". And in our corpus?
> head(tsorted)
allwords
the a to and in of
65009 30381 29563 18613 16440 12840
Stripping out all the "normal" words like "the" and "and" to find the first domain-specific word gives us a bit of a conundrum ... starting at rank # 8 we have the following three words:
for class xamarin
10427 10216 10079
"for" doesn't appear in the top 20 words as listed by VSauce, so either that's so highly ranked because it is also a programming keyword (ie. for loops), or the first domain-specific word is class followed closely by Xamarin :)
Anyways, this was just a bit of fun ... if you have any other ideas for different insights that could be gleaned, feel free to let me know on twitter!
[1]: technically, only conceptual documentation, recipes, and some release notes (as some older ones are still in HTML format). doesn't include samples and api documentation for simplicity's sake.
[2]: yes, this tokenize function could probably stand to be a bit more sophisticated. But some spot-testing showed that it was roughly good enough for this light analysis :)